

O JavaScript é uma caixinha de surpresas, essa parece ser uma linguagem extremamente simples que roda em todos os lugares. Mas é justamente essa versatilidade que torna o JS cada vez mais complexo.
Há um tempo atrás publiquei uma sequencia de 10 artigos sobre como o NodeJS funciona por baixo dos panos. E muito do que eu falei ali não se limita apenas ao NodeJS, mas sim ao JavaScript como um todo.
Por exemplo, o V8 é o engine que está por trás dos principais avanços de performance que o JavaScript teve ao longo dos anos, e isso veio graças aos avanços do browser (principalmente do Chrome).
Vamos entender o que foi adicionado recentemente ao V8, que pode ser muito benéfico para aplicações que tem vida curta, como CLIs e pequenos sites. Estamos falando do novo compilador super rápido chamado sparkplug!
Entendendo o V8
O V8 é a principal razão pela qual temos hoje um JavaScript extremamente rápido. Para alcançar esse patamar de eficiência, o V8 foi aprimorado ao longo de quase uma década para extrair o máximo possível de todas as etapas da construção de uma aplicação.
Estas etapas são o que chamamos de pipeline de compilação. Pense nela como uma sequencia de passos que a sua aplicação (o seu código) percorre para se tornar um código que é executável pelo browser e, consequentemente, pelo computador.
Eu não vou entrar em detalhes de como ele funciona aqui, porque eu já fiz isso na parte 4 da minha sequencia de artigos, mas hoje, temos a seguinte pipeline:
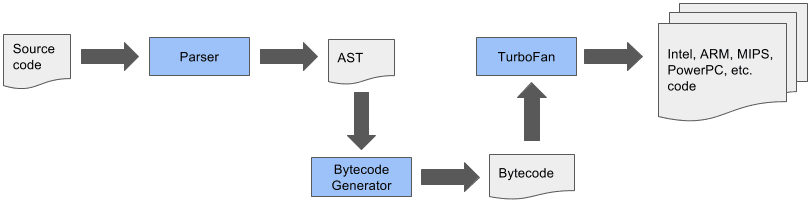
Veja que temos três etapas principais, a primeira é o parser de código, onde o código é interpretado de texto para uma representação intermediária chamada de bytecode (entenda mais sobre ele aqui) e passada para um outro interpretador chamado Ignition. O trabalho do Ignition é justamente otimizar os bytecodes para que o próximo compilador possa otimizá-lo ainda mais.
Em suma, o Ignition vai pegar o código completo em bytecode e vai otimizá-lo em uma única passada e ai sim passar para a próxima etapa que é o Turbofan.
O Turbofan é o compilador de otimização do V8, ele é dividido em camadas que operam para otimizar diferentes partes do código em diferentes momentos, além de gerar o código final para diferentes arquiteturas de sistema.
O que temos de novo
Desde 2016 o time do V8 vem notando que os gargalos de velocidade e performance do JavaScript estão acontecendo antes da compilação do código pelo Turbofan, ou seja, no início da pipeline.
Apesar de o Ignition ser bastante otimizado e otimizar o código em uma passada única, o que faz com que ele possa ser servido para o browser e executado de forma instantânea, ainda sim a performance não se mostrava satisfatória.
Isso veio a tona com uma alteração na forma como eles estavam medindo a performance, passaram a não utilizar mais benchmarks chamados de sintéticos (como ferramentas de teste tipo Octane) e começaram a usar dados reais de navegação para medir as performances de sites e do próprio engine.
O problema aqui é que existem coisas que não podem ser mais otimizadas do que já estão, por exemplo, o parser do V8 é bastante rápido, mas existem coisas que um parser precisa fazer que não podem ser simplesmente removidas da pipeline.
Além disso, com um modelo de dois compiladores na pipeline, não era possível fazer muita divisão e aumentar ainda mais a performance, isso porque a única forma de tornar tudo mais rápido seria remover as passagens de otimização o que, no final, acaba só por reduzir a performance ainda mais.
A solução, criar um novo compilador e colocar no meio dos dois:

Esse compilador foi chamado de Sparkplug.
O que é o Sparkplug?
O objetivo maior do Sparkplug é ser rápido, mas muito rápido mesmo. Ele é tão rápido que é possível ignorar quase que completamente o tempo de compilação e executar uma recompilação completa do código a qualquer momento.
O segredo para isso, na verdade, não é bem um segredo, é um hack. A realidade é que ele não compila as funções do zero, elas já foram compiladas para bytecode antes pelo Ignition, e ele já fez a maior parte do trabalho tentando descobrir quais são os valores das variáveis, se parênteses são arrow functions, transformando destructurings em atribuições e muito mais.
A grande sacada é que o Sparkplug não vai gerar nenhuma representação intermediária (chamada de IR). A IR é basicamente um código que é o meio termo entre código de máquina e o bytecode, geralmente são agrupados em trios de instruções e são muito comuns na maioria dos compiladores. Ao invés disso, o código pula algumas etapas e é compilado diretamente para a máquina.
Um fato interessante é que o Sparkplug é, na verdade, um grandeswitchdentro de umforque, basicamente, lê cada bytecode individualmente e manda a instrução para a geração do código de máquina
Isso é ótimo para velocidade, mas infelizmente não é possível otimizar muita coisa só com essas informações. Por isso o Sparkplug é um compilador sem otimizações.
Então qual é o motivo disso tudo, já que ele não otimiza o código? A grande ideia da adição do Sparkplug é que, mesmo sendo somente uma serialização do parser, ela ainda é útil, porque pré-compila todas as etapas que não poderiam ser otimizadas no interpretador em si. Dessa forma temos um aumento grande de performance só por remover esses pequenos passos não otimizáveis no início.
Segundo o time do V8, os ganhos de performance do Sparkplug são de 5-15% a mais do que sem o compilador!
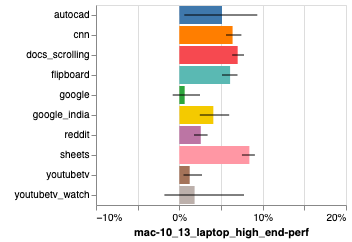
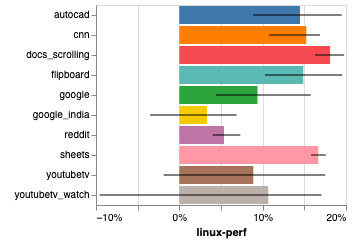
Dê uma lida no artigo original que tem muito mais informações sobre como o Sparkplug mantém essa compatibilidade já com todo o ecossistema existente!